
In the previous installment (The Data Centric Revolution: The Evolution of the Data Centric Revolution Part One), we looked at some of the early trends in application development that foreshadowed the data centric revolution, including punched cards, magnetic tape, indexed files, databases, ERP, Data Warehouses and Operational Data Stores.
foreshadowed the data centric revolution, including punched cards, magnetic tape, indexed files, databases, ERP, Data Warehouses and Operational Data Stores.
In this installment, we pick up the narrative with some of the more recent developments that are paving the way for a data centric future.
Master Data Management
Somewhere along the line, someone noticed (perhaps they harkened back to the reel-to-reel days) that there were two kinds of data that are, by now, mixed together in the databased application: transactional data and master data. The master data was data about entities, such as Customers, Vendors, Equipment, Fixed Assets, or Products. This master data was often replicated widely. For instance, every order entry system has to have yet another Customer table because of integrity constraints, if nothing else.
If you could just get all the master data in one place, you’d have made some headway. In practice, it rarely happened. Why? In the first place, it’s pretty hard. Most of the MDM packages are still using older, brittle technology, which makes it difficult to keep up with the many and various end-points to be connected. Secondly, it only partially solved the problem, as each system still had to maintain a copy of the data, if for nothing else, for their data integrity constraints. Finally, it only gave a partial solution to the use cases that justified it. For example, the 360o view of the customer was a classic justification, but people didn’t want a 360 o view of the master data; they wanted to see the transaction data. Our observation is that most companies that had the intention to implement several MDMs gave up after about 1 ½ years when they found out they weren’t getting the payout they expected.
Canonical Message Model
Service Oriented Architecture (SOA) was created to address the dis-economy in the system integration space. Instead of point-to-point interfacing, you could send transactional updates onto a bus (the Enterprise Service Bus), and allow rules on the bus to distribute the updates to where they are needed.
The plumbing of SOA works great. It’s mostly about managing messages and queues and making sure messages don’t get lost, even if part of the architecture goes down. But most companies stalled out on their SOA implementations because they had not fully addressed their data issues. Most companies took the APIs that each of their applications “published” and then put them on the bus as messages. This essentially required all the other end-points to understand each other. This was point-to-point interfacing over a bus. To be sure, it is an improvement, but not as much as was expected.
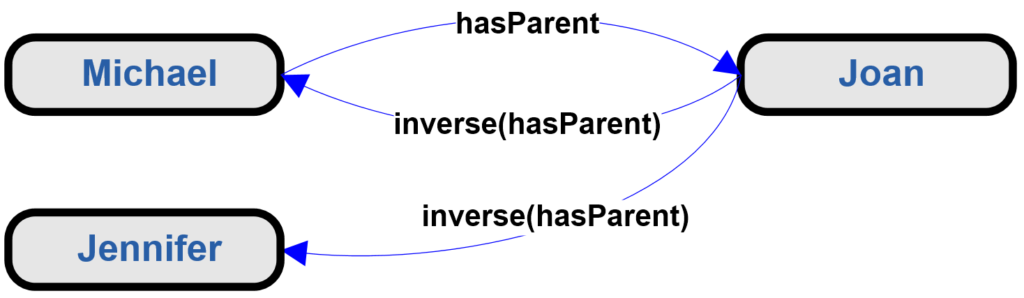
Enter the Canonical Message Model. This is a little-known approach that generally works well, where we’ve seen it applied. The basic concept is to create an elegant [1] model of the data that is to be shared. The trick is in the elegance. If you can build a simple model that captures the distinctions that need to be communicated, there are tools that will help you build shared messages that are derived from the simple model. Having a truly shared message is what gets one out of the point-to-point trap. Each application “talks” through messages to the shared model (which is only instantiated “in motion,” so the ODS problem versioning is much easier to solve), which in turn “talks” to the receiving application.


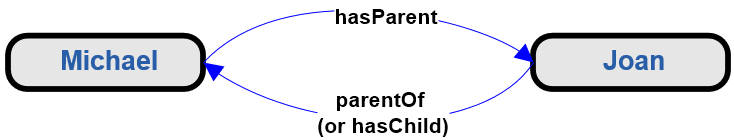
 any one at any time, but some are more prone to it than others. By the time Appliosclerosis has metastasized it may be too late, isolated and entrenched data models may already be firmly established in various vital departments, and extreme rationalization therapy may be the only option, perhaps followed by an intense taxo regimen.
any one at any time, but some are more prone to it than others. By the time Appliosclerosis has metastasized it may be too late, isolated and entrenched data models may already be firmly established in various vital departments, and extreme rationalization therapy may be the only option, perhaps followed by an intense taxo regimen.
 there is the potential that each database is small enough to be manageable.
there is the potential that each database is small enough to be manageable. humans that are typically between a few feet and 7 ft. tall and will only climb a few sets of stairs at a time, etc.
humans that are typically between a few feet and 7 ft. tall and will only climb a few sets of stairs at a time, etc.