
Person uses language. Person speaks language. Person learns language. We spend the early years of life learning vocabulary and grammar in order to generate and consume meaning. As a result of constantly engaging in semantic generation and consumption, most of us are semantic savants. This Meaning-First approach is our default until we are faced with capturing meaning in databases. We then revert to the Structure-First approach that has been beaten into our heads since Codd invented the relational model in 1970. This blog post presents Meaning-First data modeling for semantic knowledge graphs as a replacement to Structure-First modeling. The relational model was a great start for data management, but it is time to embrace a radical return to simplicity: Meaning-First data modeling.
Person learns language. We spend the early years of life learning vocabulary and grammar in order to generate and consume meaning. As a result of constantly engaging in semantic generation and consumption, most of us are semantic savants. This Meaning-First approach is our default until we are faced with capturing meaning in databases. We then revert to the Structure-First approach that has been beaten into our heads since Codd invented the relational model in 1970. This blog post presents Meaning-First data modeling for semantic knowledge graphs as a replacement to Structure-First modeling. The relational model was a great start for data management, but it is time to embrace a radical return to simplicity: Meaning-First data modeling.
This is a semantic exchange, me as a writer and you as a reader. The semantic mechanism by which it all works is comprised of a subject-predicate-object construct. The subject is a noun to which the statement’s meaning is applied. The predicate is the verb, the action part of the statement. The object is also generally a noun, the focus of the action. These three parts are the semantic building blocks of language and the focus of this post, semantic knowledge graphs.
In Meaning-First semantic data models the subject-predicate-object construct is called a triple, the foundational structure upon which semantic technology is built. Simple facts are stated with these three elements, each of which is commonly surrounded by angle brackets. The first sentence in this post is an example triple. <Person> <uses> <language>. People will generally get the same meaning from it. Through life experience, people have assembled a working knowledge that allows us to both understand the subject-predicate-object pattern as well as what people and language are. Since computers don’t have life experience, we must fill in some details to allow this same understanding to be reached. Fortunately, a great deal of this work has been done by the World Wide Web Consortium (W3C) and we can simply leverage those standards.
Modeling the triple “Person uses language” in Figure 1, Triple diagram using arrows and ovals is a good start. Tightening the model by adding formal definitions makes it more robust and less ambiguous. These definitions come from gist, Semantic Arts’ minimalist upper level ontology. The subject, <Person>, is defined as “A Living Thing that is the

Figure 1, Triple diagram
offspring of some Person and that has a name.” The object, <Language>, is defined as “A recognized, organized set of symbols and grammar”. The predicate, <uses>, isn’t defined in gist, but could be defined as something like “Engages with purpose”. It is the action linking <Person> to <Language> to create the assertion about Person. Formal definitions for subjects and objects are useful because they are mathematically precise. They can be used by semantic technologies to reach the same conclusions as can a person with working knowledge of these terms.
Surprise! This single triple is (almost) an ontology. This is almost an ontology because it contains formal definitions and is in the form of a triple. Almost certainly, it is the world’s smallest ontology, and it is missing a few technical components, but it is a good start on an ontology all the same. The missing components come from standards published by the W3C which won’t be covered in detail here. To make certain the progression is clear, a quick checkpoint is in order. These are the assertions so far:
- A triple is made up of a <Subject>, a <Predicate>, and an <Object>.
- <Subjects> are always Things, e.g. something with independent existence including ideas.
- <Predicates> create assertions that
- Connect things when both the Subject and Object are things, or
- Make assertions about things when the Object is a literal
- <Objects> can be either
- Things or
- Literals, e.g. a number or a string
These assertions summarize the Resource Description Framework (RDF) model. RDF is a language for representing information about resources in the World Wide Web. Resource refers to anything that can be returned in a browser. More generally, RDF enables Linked Data (LD) that can operate on the public internet or privately within an organization. It is the simple elegance embodied in RDF that enables Meaning-First Data Modeling’s radically powerful capabilities. It is also virtually identical to the linguistic building blocks that enabled cultural evolution: subject, predicate, object.
Where RDF defines the framework that defines the triple, Resource Description Framework Schema (RDFS) provides a data-modeling vocabulary for building RDF triples. RDFS is an extension of the basic RDF vocabulary and is leveraged by higher-level languages such as Web Ontology Language (OWL), and Dublin Core Metadata Initiative (Dcterms). RDFS supports constructs for declaring that resources, such as Living Thing and Person, are classes. It also enables establishing subclass relationships between classes so the computer can make sense of the formal Person definition “A Living Thing that is the offspring of some Person and that has a name.”
Here is a portion of the schema supporting the opening statement in this post,
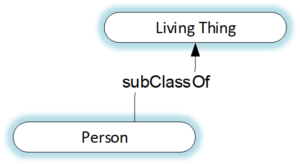
Figure 2, RDFS subclass property
“Person uses Language”. For simplicity, the 'has name' portion of the definition has been omitted from this diagram, but it will show up later.Figure 2 shows the RDFS subClassOf property as a named arrow connecting two ovals. This model is correct as it shows the subClassOf property, yet it isn’t quite satisfying. Perhaps it is even a bit ambiguous because through the lens of traditional, Structure-First data modeling, it appears to show two tables with a connecting relationship.
Nothing could be further from the truth.
There are two meanings here and they are not connected structures. The Venn diagram in Figure 3, RDFS subClassOf Venn diagram more clearly shows the Person set is wholly contained within the set of all Living
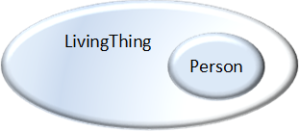
Figure 3, RDFS subClassOf Venn diagram
Things so it is also a Living Thing. There is no structure separating them. They are in fact both in one single structure; a triple store. They are differentiated only by the meaning found in their formal definitions which create membership criteria of two different sets. The first set is all Living Things. The second set, wholly embedded within the set of all Living Things, is the set of all Living Things that are also the offspring of some Person and that have a name. Person is a more specific set with criteria that causes a Living Thing to be a member of the Person set but is also still a member of the Living Things set.
Rather than Structure-First modeling, this is Meaning-First modeling built upon the triple defined by RDF with the schema articulated in RDFS. There is virtually no structure beyond the triple. All the triples, content and schema, commingle in one space called a triple store.
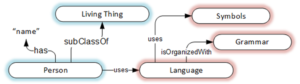
Figure 4, Complete schema
Here is some informal data along with the simple ontology’s model:
Schema:
- <Person> <uses> <Language>
Content:
- <Mark> <uses> <English>
- <Boris > <uses> <Russian>
- <Rebecca> <uses> <Java>
- <Andrea> <uses> <OWL>
Contained within this sample data lies a demonstration of the radical simplicity of Meaning-First data modeling. There are two subclasses in the data content not currently
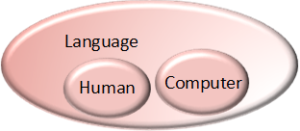
Figure 5, Updated Language Venn diagram
modeled in the schema, yet they don’t violate the schema. The Figure 5 shows subclasses added to the schema after they have been discovered in the data. This can be done in a live, production setting without breaking anything! In a Structure-First system, new tables and joins would need to be added to accommodate this type of change at great expense and over a long period of time. This example just scratches the radical simplicity surface of Meaning-First data modeling.
Stay tuned for the next installment and a deeper dive into Meaning-First vs Structure-First data modeling!
Hi Richard, thanks for your comment.
My point is that children learn semantics within the context of growing up through observation and experience. It isn’t until they enter grammar school that they learn the underlying semantic mechanics is what they have been using all along. The mechanics underlying human communication is in fact the schema by which we transfer ideas and it is so ingrained that we don’t have to parse it or even think of it as a schema. It is a schema learned by rote over many years and extended by speakers of each human language over the course of time. The slow change to the language and its’ schema has allowed it to become ingrained in human experience.
The machine sort of is an idiot savant that only has the information we provide and the semantic approach about which I write bridges the gap between computers and humans. My reference to radical simplicity is that, unlike traditional Meaning-First approaches, semantic technologies leverage the innate schema speakers of language use everyday. The traditional approach has been to construct arbitrarily complex structures comprised of hundreds to thousands of tables each with tens to hundreds of columns, an exercise that takes months if not years. Taking this complex exercise out of the practice of managing data is orders of magnitude less complex.
Having spent decades designing and implementing systems using the arbitrary complexity required by the Structure-First paradigm, my experience is that of radical simplicity when the semantic Meaning-First approach is used which regularly takes weeks or months, not years. This is not to say that the task of understanding the elements of meaning required to support an enterprise is simple. In my mind a reduction from months-to-years down to weeks-to-months is a metric that supports a pretty radical change to the simplistic.
I don’t have a response to your comment about those designing models being data illiterate and the result being parlor tricks because in over thirty years in the industry, even with bad models, I have not seen evidence of either of these.