More times than not we receive pushback on the use of RDF (the standard model for data exchange on the web) being difficult. However, the simplicity of triplestores (Subject – Predicate – Object) and logically composing queries with the written language make this form ideal for technical business users, capability owners, and data scientists alike. By possessing the deep business knowledge, a business user’s inquisitive nature result in an endless list of questions to answer. Why wait for an engineer to get the request weeks later when greater accessibility can be achieved with semantic web capabilities?
We bring this idea to enriching the meaningfulness of capturing these answers by making some thoughtful RDF for enhanced interrogation in a git repository.
Motivation
A while back cURL’s creator, Daniel Stenberg, tweeted some stats on cURL’s git repository.
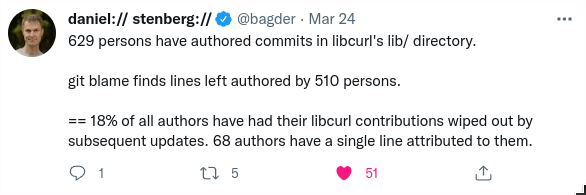
I have a pretty good idea about how he answered those questions. I bet he used some tools like sed, awk, and grep. If I had to answer those questions I too might use those CLI utilities with a throw away shell pipeline. But I wondered what it would be like to answer those questions semantic web style.
What
In order to answer questions semantic web style you first have to find or make some thoughtful RDF. I say “thoughtful” because it is possible, though mostly not desirable, to use the semantic web stack (RDF/SPARQL/OWL/SHACL, etc.) without doing much domain modeling.
In our case we can easily get some structured data to start with. Here is a git commit I just made:
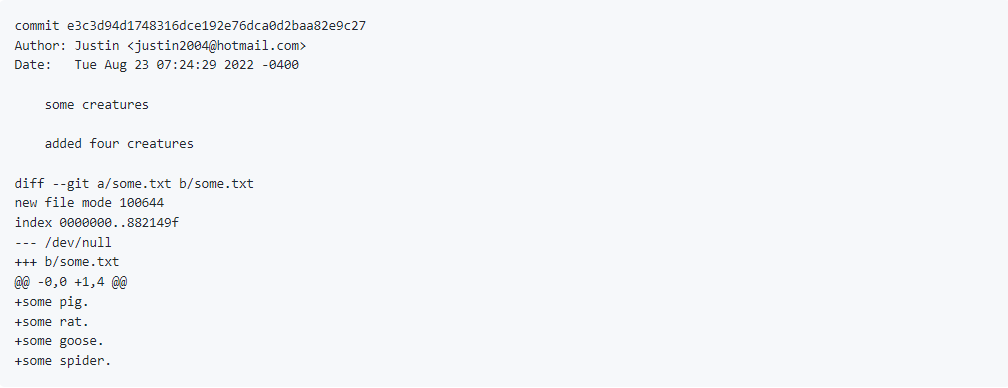
Notice how compact that representation is. The meat of that text is the unified output format of the diff tool. If you work with git much you probably recognize what most of that is. But the semantic web isn’t about just allowing you to work with data you already know how to decipher. To participate in the semantic web we need to unpack this compact application-centric representation into a data-centric representation so that others don’t need to do the deciphering. In the semantic web we want data to wear its meaning on its sleeve.
That compact representation is fine for the diff and patch tools but doesn’t really check any of these boxes:

Ok, I ran my conversion tool on that commit and it transformed that representation into a thoughtful RDF graph.
Let’s take a look (using RDFox’s graph viz):
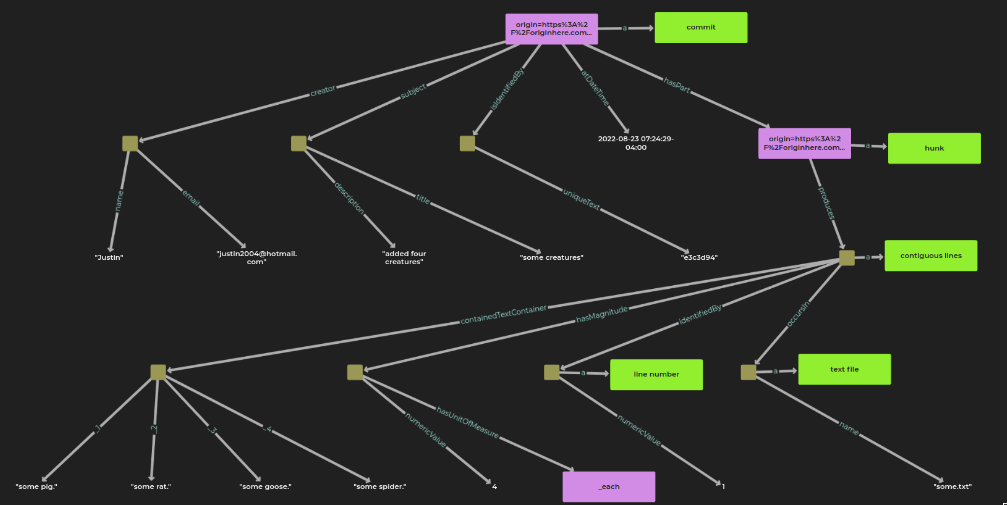
You’ll notice that commits have parts: hunks.
Those hunks, when applied, produce contiguous lines.
Those contiguous lines:
occur in a text file with a name
are identified by a line number
have a magnitude with a unit of measure (line count)
and have the literal contained text
Note that I’ve used Wikidata entities because Wikidata is a nice hub in the semantic web. Here is a Wikidata subgraph with labels that are relevant for the RDF I’ve produced:
 By the way, don’t let those Q numbers scare you. I don’t memorize them (well I do have wd:Q2 memorized since it is pretty special). I use auto completion in my text editor and Wikidata has it here too. You just type wd: then press control-enter then type what you want. Also, Wikidata has some good reasons for using opaque IRIs.
By the way, don’t let those Q numbers scare you. I don’t memorize them (well I do have wd:Q2 memorized since it is pretty special). I use auto completion in my text editor and Wikidata has it here too. You just type wd: then press control-enter then type what you want. Also, Wikidata has some good reasons for using opaque IRIs.
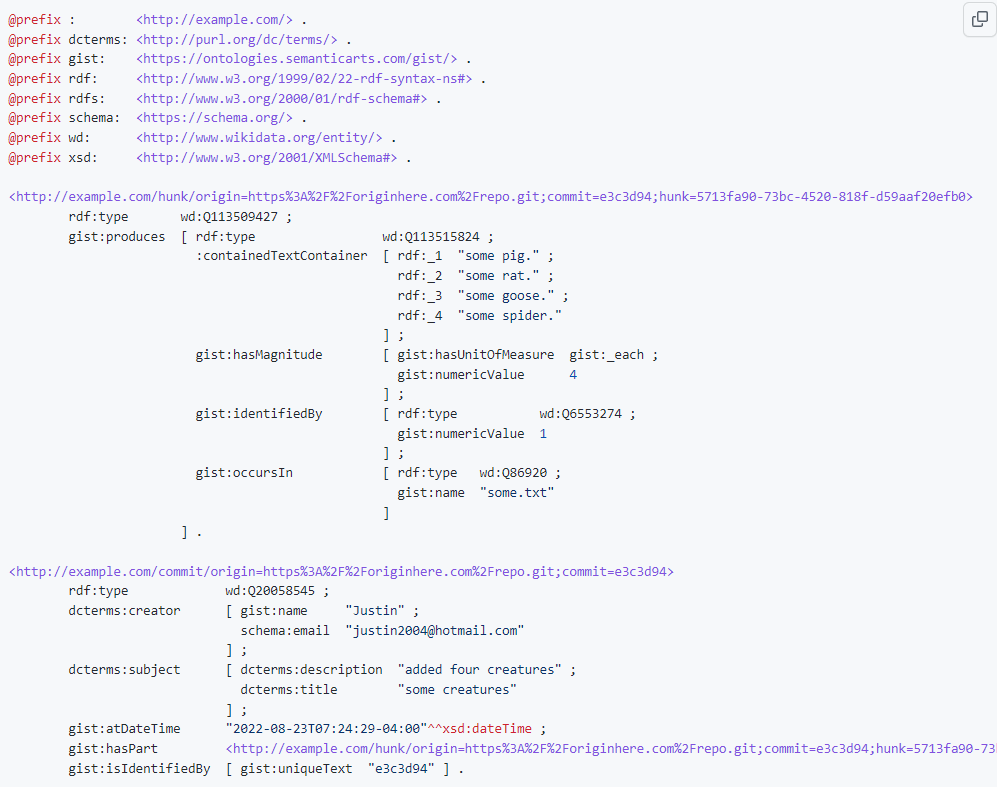
Here is the RDF graph (the same one as in the image above) in turtle serialization:
Here is another commit:
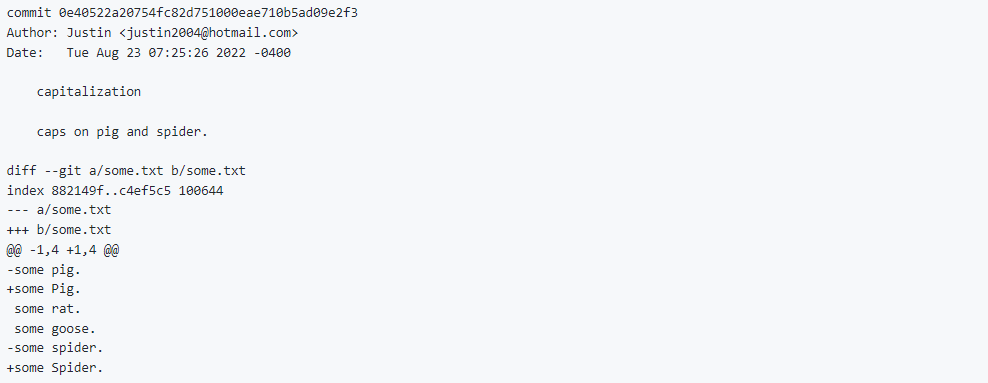
And the RDF:


You’ll notice that this commit does a little more. The hunk produces contiguous lines as before. The hunk also affects contiguous lines. That is because this commit does not add a new file; it changes an existing file by replacing some contiguous lines with some other contiguous lines.
Why
At this point maybe you’re wondering why the data isn’t more “direct.” The RDF seems to spread things out and use generic predicates (produces, occurs in, etc.). That is intentional.
My conversion utility does use some intermediate “direct” data:
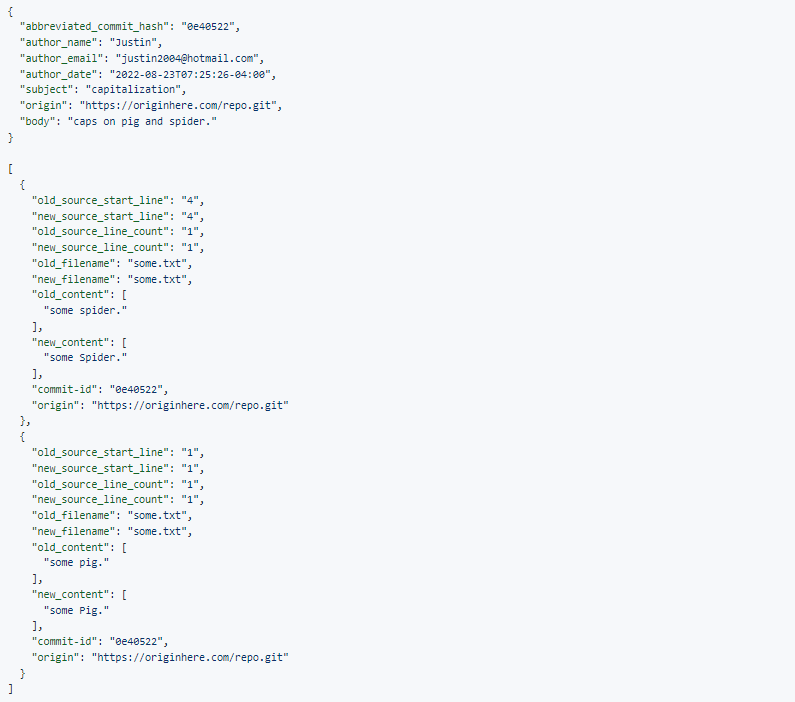
But that data does not snap together with other data like RDF does. It does not have formal semantics. It has not unpacked the meaning of the data. It is more like an ad hoc projection of data. It is not something I would want to pass around between applications.
There are some nice things about using RDF to express the content of a git repository. This is not a comprehensive list but rather just stuff that I thought of while doing this project:
(1)
You can start anywhere with queries.
If you want to find all things with names you just:
select * where {
?s gist:name ?name .
}
If you want to find all files with names:
select * where {
?s a wd:Q86920 .
?s gist:name ?name .
}
You don’t need to know structurally where these “fields” live.
(2)
You define things in terms of more primitive things.
For example, if you look on Wikidata you’ll see that commit is defined in terms of changeset, and version control. Hunk is defined in terms of diff unified format and line.
Eventually definitions bottom out in really primitive things that aren’t defined in terms of anything else.
One of the reasons this is helpful is that you can query against the more primitive things and get back results containing more composite things (built up from the more primitive things).
(3)
You are encouraged (if you use a thoughtful upper ontology such as Gist) to unpack meaning.
I think of the semantic web as something like the exploded part diagram for the web’s data.
Yes, it takes up more space than a render of fully assembled thing but all the components you might want to talk about are addressable and their relationship to other components is evident.
One example of how not unpacking makes question answering harder is how Wikidata packs up postal code ranges with an en dash (–).
If you query Wikidata to see what region has postal code “10498” allocated to it you won’t find any results. You’ll instead have to write a query to find a postal code (some of them are really a range of postal codes designated with an en dash) by making a procedure that gets the start and stop symbols (numbers in this case) and enumerates the range and does a where in or something similar.
If you require users to unpack all your representations before they use them then maybe they’ll lose interest and move on to something else.
A thoughtful ontology will help you carve the world at its joints, putting points of articulation between things, by having a thoughtful set of generic predicates. You might not be using a thoughtful ontology if you can connect any two arbitrary things with a single edge.
The unified output format for diff works well for the git and patch programs but not for humans asking questions.
Sure, unpacked representations mean more data (triples) but the alternatives (application-centric data, LPGs/RDF-Star, etc.) are like bodge wires:

They are acceptable for your final act, maybe , but not something you’d want to build upon.
(4)
RDF allows for incremental enrichment.
As a follow up to this project I think it would be interesting to transform CWEs (Common Weakness Enumeration) and CVEs (Common Vulnerabilities and Exposures) into RDF and connect them to the git repositories where the vulnerability producing code is.
(5)
More people can ask questions of the data.
SPARQL is a declarative query language. The ease of using SPARQL has a bit to do with the thoughtfulness of the domain modeling.
Below I pose several questions to the data and I obtain answers with SPARQL.
Answering Questions About cURL
The cURL git repo has about 29k commits and commits going back to 1999.
My conversion tool turned it into just under 8 million triples in 70 minutes. I haven’t focused on execution efficiency yet. I wanted to run queries against the data to get a feel the utility of this approach before I refine the tool.
Let’s answer some questions about the development of cURL.
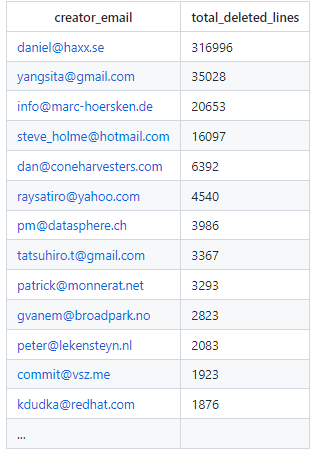
How many deleted lines per person?
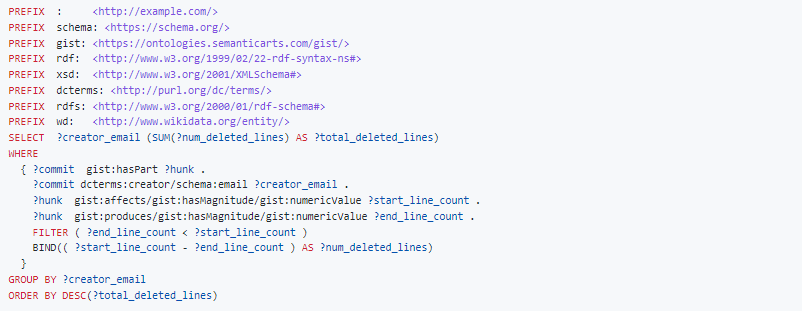
Result:
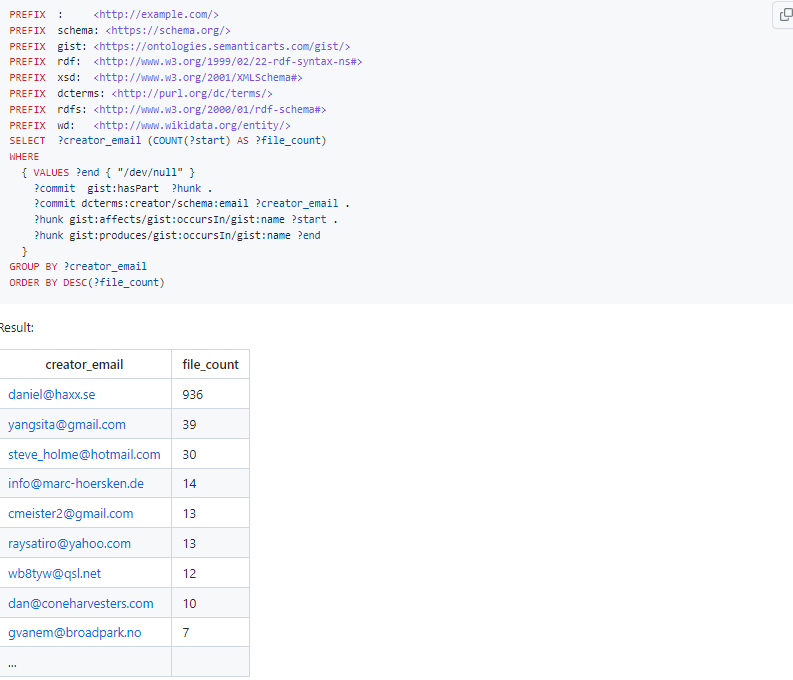
How many deleted files per person?
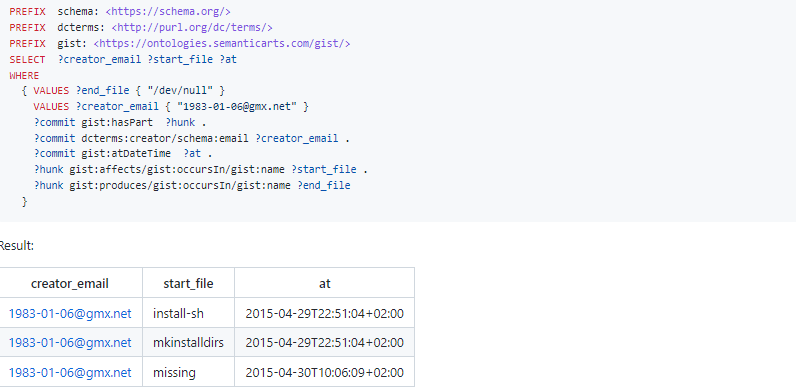
What files did a particular person delete and when?
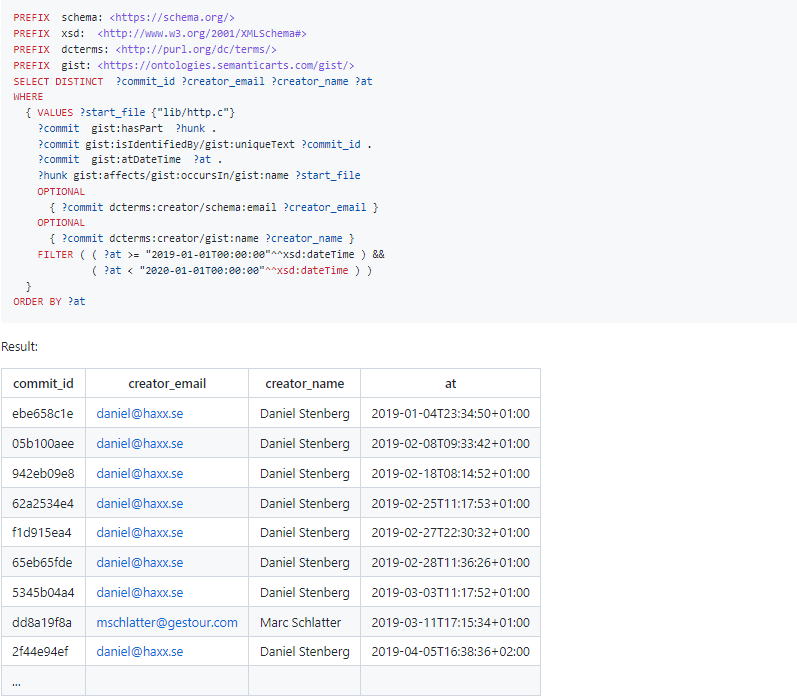
Which commits affected lib/http.c in 2019 only?
Which persons have authored commits with the same email but different names?
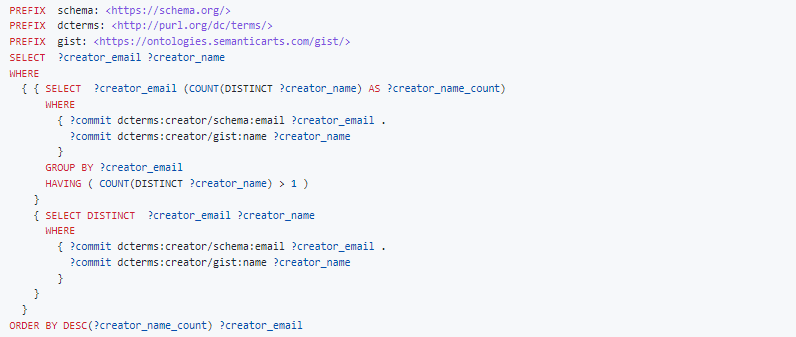
Result:
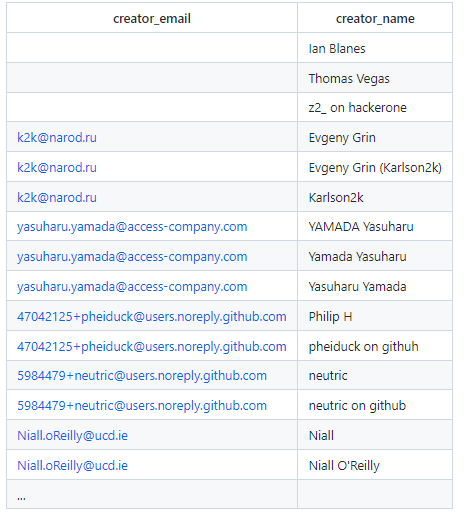
Which persons have authored commits with the same name and different email?
Result:

Which persons have authored commits in libcurl’s lib/ directory (this includes deleting something in there)?
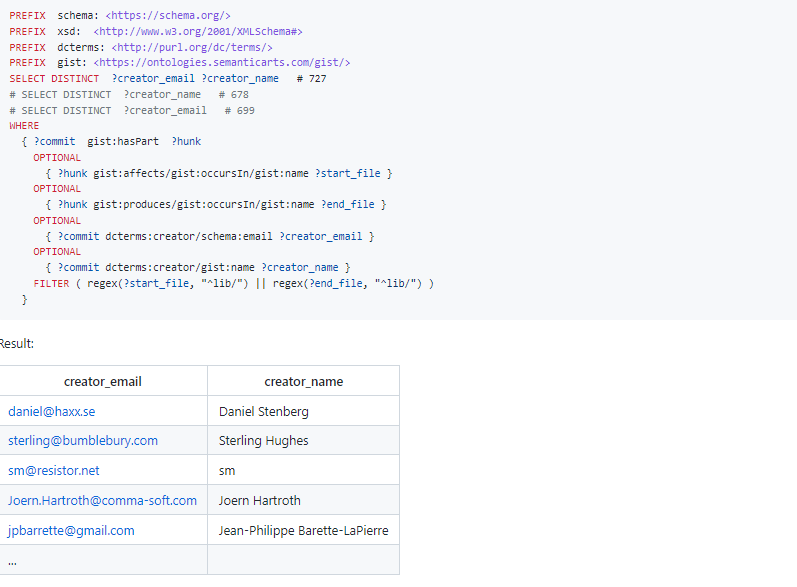
And depending on how you count the people the query finds between 678 and 727 people that authored commits in libcurl’s lib/ directory. That was Daniel’s first question. He got 629 with his method but that was a few months ago and I don’t know exactly what his method of counting was. He may not have included the act of deleting a file in that directory like I did.
To answer his next three questions I’d need to record each commit’s parent commit (I don’t yet — one of my many TODOs) and simulate the application of hunks in SPARQL or add the output of git blame to the RDF. Daniel likely used the output of git blame. I’ll think about adding it to the RDF.
How
In another blog post I might describe how the conversion utility works. It is written in Clojure and it uses SPARQL Anything (which is built upon Apache Jena). I expect to push it to Github soon.
Closing Thoughts
It is fun to imagine having all the git repos in Github as RDF graphs in a massive triplestore and asking questions with SPARQL.
In my example queries I didn’t make use of the fact that each source code line is in the RDF. Most triplestores have full text search capabilities so I’ll write some queries that make use of that too. In general I haven’t been overly impressed with search built-into Gitlab and Bitbucket (I haven’t used Github’s search much) so I wonder if keeping an RDF representation with full text search would be a useful approach. I’d love to see a SPARQL endpoints for searching hosted git platforms!
I think this technique could be applied to other application-centric file formats. SPARQL Anything gets you part of the way there for several file formats but I’d like to hear if you have other ideas.
Join the discussion on twitter!











