
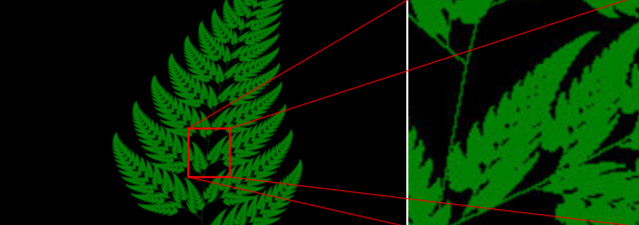
Fractal geometry creates beautiful patterns from simple recursive algorithms. One of the things we find so appealing is their “self-similarity” at different scales. That is, as you zoom in to look at a detail under more magnification you see many of the same patterns that were visible when zoomed out at the macro level.
After decades of working with clients at large organizations, I’ve concluded that they secretly would like to have a fractal approach to managing all their data. I say this desire is secret for several reasons:
- No one has ever used that term in my presence
- What they currently have is 180 degrees away from a fractal landscape
- They probably haven’t been exposed to any technology or approach that would make this possible
And yet, we know this is what they want. It exists in part in a small subset of their data. The ability to “drill down” on predefined dimensions gives a taste of what is possible, but it is limited to that subset of the data. It exists in small measure in any corpus made zoom-able by faceted categorization., but it is far from the universal organizing principle that it could be. Several of the projects we have worked on over the last few years have allowed us to triangulate in on exactly this capability. This fractal approach leads us to information-scapes that have these characteristics:
- They are understandable
- They are pre-conditioned for easy integration
- They are less likely to be loaded with ambiguity
The Anti-fractal data landscape
The data landscape of most large enterprises looks alike:
- There are tens of thousands to hundreds of thousands of database tables.
- In hundreds to thousands of applications
- In total there are hundreds of thousands to millions of attributes
There is nothing fractal about this. It is a vast, detailed data landscape, with no organizing principle. The only thing that might stand in for an organizing principle is the bounds of the application, which actually makes matters worse. The presence of applications allow us to take data that is similar, and structure it differently, categorize it differently, and name it differently. Rather than provide an organizing principle, applications make understanding our data more difficult.
And this is just the internal/ structured data. There is far more data that is unstructured (and we have nearly nothing to help us now with unstructured data), external (ditto) and “big data” (double ditto).