
I’m writing this on an airplane as I’m watching the South Park episode where the lads attempt to save classic films from their directors who want to re-release them to make them more politically correct and appeal to new audiences. (The remake of Saving Private Ryan where all the guns were replaced with cell phones, for instance). So it’s with great trepidation that I describe the motivation and result of the “re-release” of DBBO. We’ve been teaching “Designing and Building Business Ontologies” for over 10 years. We have been constantly updating, generally adding more material. What we found was that while the material was quite good, we had to rush to get through it all. Additionally, we added material that caused us to explain concepts we hadn’t yet covered in order to make a particular point. And of course there was ever more material we wanted to add. Also we were interested in modularizing the material, so that people could take less than the full course if that’s what they needed. We essentially created a dependency graph of the concepts we were covering and dramatically re-sequenced things. This shone a light on a number of areas where additional content was needed. Our first trial run was an internal training project with Johnson & Johnson. This group at J&J had already built some ontologies in Protégé and TopBraid and had training in Linked Open Data and SPARQL. So we were able to try out two aspects of the new modularity: if students had the right pre-requisites, they could start in the middle somewhere. However, with the new packaging, would it be possible to spread the training out over a longer period of time and still give the students something they could use in the short term? So with J&J we did the new days 3, 4 and 5 in two sessions separated by two weeks. I’m happy to report that it went very well. Then in May we had our first public session. We’ve decided to have days 1-3 on Wednesday – Friday and days 4-6 on the following Monday – Wednesday. Some people who really want to learn all there is to learn can power through all six sessions contiguously. There is a lot to do in the Fort Collins area, and we’ve heard the break is good for consolidating what was learned before getting back into it. Others have decided to take days 1-3 and come back later to finish up days 4-6. The course is now more logically structured, not quite as rushed (although there is a lot of material still) hard to imagine with all the hands on work, we created nearly 2,000 slides, 90% of which were new or substantially upgraded.Learn more or sign up for DBBO. Dave McComb
The Whiteboard
Semantic Tech meets Data Gov
Watch out world! Eric Callmann, a vet of data governance, recently joined the Semantic Arts team as a consultant. We like his fresh and unique perspective on how to use semantic technology to help manage the mass amounts of data that could potentially drive us all mad. 
We did a little Q&A with Eric to find out more about him and his take on #SemTech2013.
SA: What’s your background and how did we find you?
Eric Callmann: My background is in developing information quality programs at large information services companies. I found my way to Semantic Arts by way of a
n Information Governance Council where I met Dave McComb.
SA: What made you want to take the leap into semantics?
EC: The arena of semantics and ontologies is at the forefront of emerging, next generation tools to help us manage the larger and larger amounts of data that are being produced. Also the development of data governance programs had me thinking that as the realm of semantics grows, there is a greater need to govern and ensure high quality triples created within ontologies. I shared this with Dave and he felt the same way. As a result, I joined Semantic Arts in May and have been drinking from the semantic fire hose ever since.
SA: So we sent you to SemTech in June, what was your experience?
EC: I was fortunate to be able to attend SemTech2013. For someone who is not a diehard techie (e.g. I don’t build apps, manage databases, install hardware, etc.), rather a business person who knows how to leverage technology, the event was a way to see into the future.
SA: What do you mean by ‘seeing into the future’?
EC: What I mean by being able to see into the future is that semantic technologies is and will continue to make all of our lives on the internet and within enterprises easier to find the things we need. For example, Walmart presented their use of Semantics to improve the search experience on Walmart.com. They are leveraging publicly available information, such as Wikipedia, to help the search engine understand the context of what one is searching for. Throughout the conference there were numerous presentations about using this technology in new ways to improve analytics and develop new services. To say the least, the amount of innovation and entrepreneurship that is happening in this space is astounding. There are already new services that are being offered that use this technology such as Whisk.com that allows you to find a recipe and have your grocery list created automatically at your favorite grocery store (Note: This is only available in the UK…lucky Londoners). If Walmart is doing it, it is pretty obvious that Google and Yahoo! are leveraging this great technology in really cool ways too. More from Eric’s perspective in the future. We are excited to have Eric on board! If you have any questions for Eric, make sure to shoot him an email: [email protected]
The new and improved DBBO Training. One man’s journey…..
Let the Semantic Technology hype cycle begin
Gartner has, finally, nominated Semantic Technology as one of their Top Technology Trends. We’ve seen this movie before. We know how it ends. Indeed it was Gartner themselves who named the plot trajectory: the “hype cycle.” It’s worth a pause to reflect on why the hype cycle exists. The hype cycle suggests that a new technology follows a development growth path as predictable as egg to caterpillar to chrysalis to butterfly. In the hype cycle, the stages are: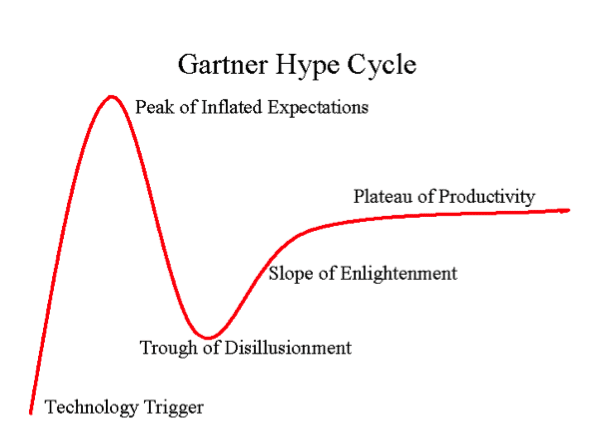 Let’s think about the underlying dynamics. At first there is a product or approach that purports to solve an existing problem. If it doesn’t, it falls off the radar. If it does, the implementer and often the implementee get bragging rights at conferences and magazines. They tout the benefits (let’s say, increased inventory turns) and some aspect of the approach that led to the benefit (let’s say, genetic algorithms). A few other firms pick up on the relative advantage being gained by the early adopter, and many actually get the connection between the approach or the technology (genetic algorithms) and the result (increased inventory turns). Up to this point there is no hype cycle, just good old-fashioned diffusion of innovation which has been widely studied since the introduction of hybrid corn in the 1930’s. In order to fuel a hype cycle you need someone hyping. Certainly some vendors will hype their solutions. But most customers are immune to this puffery, and can afford to sit on the sidelines. But when someone with the ability to move markets like Gartner weighs in, the industry is obligated to take notice. Customers, wary of missing out on the next big thing, wade in. But it is at this juncture that the connection between the feature (genetic algorithms in this example) and the benefit (increased inventory turns) gets severed. Vendors rush in to supply the new technology, and everyone is in too much of a hurry to worry about the benefits. The trough of disillusionment shows up, just as the bow wave of these projects crests. The projects complete (without benefit) or get cancelled. Disappointment is rampant. The dead are buried, companies move on. But a few projects persist. A few actually get the promised benefits. After a couple more implementation cycles, the patterns finally emerge about how to do this well. The technology is redeemed, and we are declared to be on the “slope of enlightenment.” We were helping clients with SOA design in the early days, and there was a time when the techniques and the benefits were actually connected. We found it amusing years later to see that Gartner had observed that SOA implementation was going through four phases to get to maturity. In our opinion, the fourth phase was really where companies should have started, were it not for the help they got from over-eager vendors on the bandwagon. The same was true with MDM and at least a dozen other hot technologies. That is the general pattern. How do we think it will play out in Semantic Technology? Who will gain and lose in the Semantic Technology hype cycle? Vendors of Semantic Technology products of course will be the immediate beneficiaries, as will any technology that can get the “Semantics Inside” stickers on their products in time for their next marketing campaign. As we saw with MDM, once the market shifted from professional services firms solving real problems to software vendors selling products, it was the beginning of the end. That’s not to say that the products are bad or unnecessary; it’s just that in thrall of the hype cycle customers tend to purchase first and plan later. The other constituents to benefit are the large professional services firms. We can reliably predict that firms with a bench will suddenly discover that they had semantic skills in-house (“how hard could this be?”). Anyone who can spell “ontologies” will soon become an expert. (I just noticed that even this has become easier: as of Word 2013 Microsoft finally included “ontologies” in their standard spelling dictionary, however, it looks like “ontologist” will have to wait for the next version.) So, who is harmed in this stage of the hype cycle? Most customers. Those who buy a product and then look for an application or those that believe what the newly minted semantic experts tell them. Also harmed are the firms who know what they are doing and have been delivering value all along. Recruiting, always difficult, will become more so as the gold rush plays out. And there will be pricing pressure as the wave of new ontologists puts commodity pricing pressure on the industry. I wasn’t looking forward to this day, but here we are. Let’s try to make the most of it and see how many companies we can get to the “plateau of productivity” while everyone else is slogging it out in the trough.
Let’s think about the underlying dynamics. At first there is a product or approach that purports to solve an existing problem. If it doesn’t, it falls off the radar. If it does, the implementer and often the implementee get bragging rights at conferences and magazines. They tout the benefits (let’s say, increased inventory turns) and some aspect of the approach that led to the benefit (let’s say, genetic algorithms). A few other firms pick up on the relative advantage being gained by the early adopter, and many actually get the connection between the approach or the technology (genetic algorithms) and the result (increased inventory turns). Up to this point there is no hype cycle, just good old-fashioned diffusion of innovation which has been widely studied since the introduction of hybrid corn in the 1930’s. In order to fuel a hype cycle you need someone hyping. Certainly some vendors will hype their solutions. But most customers are immune to this puffery, and can afford to sit on the sidelines. But when someone with the ability to move markets like Gartner weighs in, the industry is obligated to take notice. Customers, wary of missing out on the next big thing, wade in. But it is at this juncture that the connection between the feature (genetic algorithms in this example) and the benefit (increased inventory turns) gets severed. Vendors rush in to supply the new technology, and everyone is in too much of a hurry to worry about the benefits. The trough of disillusionment shows up, just as the bow wave of these projects crests. The projects complete (without benefit) or get cancelled. Disappointment is rampant. The dead are buried, companies move on. But a few projects persist. A few actually get the promised benefits. After a couple more implementation cycles, the patterns finally emerge about how to do this well. The technology is redeemed, and we are declared to be on the “slope of enlightenment.” We were helping clients with SOA design in the early days, and there was a time when the techniques and the benefits were actually connected. We found it amusing years later to see that Gartner had observed that SOA implementation was going through four phases to get to maturity. In our opinion, the fourth phase was really where companies should have started, were it not for the help they got from over-eager vendors on the bandwagon. The same was true with MDM and at least a dozen other hot technologies. That is the general pattern. How do we think it will play out in Semantic Technology? Who will gain and lose in the Semantic Technology hype cycle? Vendors of Semantic Technology products of course will be the immediate beneficiaries, as will any technology that can get the “Semantics Inside” stickers on their products in time for their next marketing campaign. As we saw with MDM, once the market shifted from professional services firms solving real problems to software vendors selling products, it was the beginning of the end. That’s not to say that the products are bad or unnecessary; it’s just that in thrall of the hype cycle customers tend to purchase first and plan later. The other constituents to benefit are the large professional services firms. We can reliably predict that firms with a bench will suddenly discover that they had semantic skills in-house (“how hard could this be?”). Anyone who can spell “ontologies” will soon become an expert. (I just noticed that even this has become easier: as of Word 2013 Microsoft finally included “ontologies” in their standard spelling dictionary, however, it looks like “ontologist” will have to wait for the next version.) So, who is harmed in this stage of the hype cycle? Most customers. Those who buy a product and then look for an application or those that believe what the newly minted semantic experts tell them. Also harmed are the firms who know what they are doing and have been delivering value all along. Recruiting, always difficult, will become more so as the gold rush plays out. And there will be pricing pressure as the wave of new ontologists puts commodity pricing pressure on the industry. I wasn’t looking forward to this day, but here we are. Let’s try to make the most of it and see how many companies we can get to the “plateau of productivity” while everyone else is slogging it out in the trough.
Taxonomies — Formal and Informal
We were working with a client recently who wanted to incorporate their existing taxonomies into their newly forming enterprise ontology. It was, as they say, a “teachable moment.” Not all taxonomies are created equal. At least not with regard to their being able to be integrated into an ontology. Most people start a taxonomy project with a slide in their power point deck showing the Linnean taxonomy. Some variation on this blogimage And then proceed to build indented lists and call them taxonomies. But what Carl Linnaeus knew, and we often conveniently forget, is that this taxonomy is special, in that all members of any lower order are also members of all their higher orders. That is, all dogs are carnivores, all carnivores are mammals, all mammals vertebrates, etc. This is called a formal taxonomy. The easy test for a formal taxonomy is to just ask “isa?” or more fully “is a instance of the lower level category necessarily a type of the higher level category?” at each level and if the answer is yes, then it’s a formal taxonomy. But most taxonomies are not formal. Many, especially those being developed in “Information Architecture” are “navigational” that is the taxonomy exists to help a human web visitor find what they are looking for. For instance the Google merchant taxonomy has a set of categories as follows: Baby & Toddler Nursing & Feeding Baby Bottle Nipples This may be useful to find things, but if we ask “are all members of Baby Bottle Nipple” necessarily a type of “Nursing &Feeding” is either “Nursing & Feeding” or “Baby Bottle Nipples” a type of “Baby & Toddler?” Clearly no. If we naively import informal taxonomies into our ontologies, we may get into trouble. More in a future episode.
How can I perform quality assurance on an ontology?
First, you need to know what the original objectives were for having the ontology. The more specific the objectives, the easier it is to test whether they have been met. If you never had any objectives (or requirements), it might be easier to declare success, but harder to defend what that means.
Whatever the specific objectives might be, some general things to look at include correctness, completeness, elegance and understandability. Correctness means that the classes, properties and axioms accurately characterize the subject matter being modeled. A good place to start is to run an inference engine to see if there are any logical inconsistencies. Completeness means that the ontology has the right coverage of subject matter – no important concepts are left out. Determining what should be in or out is a scoping issue that strongly depends on the ontology objectives. Elegance is the other side of the completeness coin: are there things in the ontology that are not needed? Importantly, this includes avoiding redundancy and complexity. Understandability is about the ontology being easy to learn and use. There must be high level overviews for those who don’t need the details, and an easy way to drill down to the specifics for those who do.
How can I obtain confidence that an ontology is correct?
A good place to start is to run an inference engine to see if there an any logical inconsistencies or classes that cannot possibly have any members. The former is always an error; the latter usually leads to an error. However, this is only the beginning. Plenty of errors can remain even when the ontology passes the above tests. Another good thing to do is to examine the inferred hierarchy to ensure that everything makes sense. When it does not, click to get an explanation and then track down the error. Another important technique is to create unit test data. Often an error will not show up until it is run against data. Creating test data is also a good way to test your understanding of the model; it is where the rubber hits the road. It is easy to think a portion of the ontology is right, only to find gaps and errors when creating test triples. Look at alphabetized lists of classes and properties to find likely spelling errors. You can also identify patterns that you know to be likely errors and write SPARQL queries to find them. For example, if you like to have inverses for all your object properties, you can easily find exceptions this way. Many of the most common pitfalls have been already identified and code has been written to find them; see: “Are there any tools to help find common pitfalls in ontologies?” Finally, you should check the ontology against the sources of knowledge. If you interviewed some experts, show and explain the ontology to them for feedback.
How can I ensure that an ontology is complete?
This is a question of scope. An ontology is complete if it has all the concepts and axioms that are needed. Needed for what? This depends on the intended purpose of the ontology. If you have a local, one-time need to integrate a small number of databases, then you need to include all the concepts that are covered in those databases. On the other hand, if you are building an enterprise ontology to serve as a long-term semantic foundation for your organization, then you will want to focus on only those concepts that are both essential and stable in your organization, that is, the most important concepts: the ones that have been around for decades and will be around for decades to come.
If the ontology has a fairly broad purpose and was not built to be used by any specific IT systems, a good way to check for completeness is to identify a number of possible use cases for deploying it. You might start by brainstorming possible use cases and applications that would solve critical problems that the company currently faces. Focus on those that can be solved by having the right data available. For each use case, identify the goal, inputs and outputs, and the required data to make that use case work. Then check the data requirements against the ontology to make sure they are covered. What is missing might belong in the ontology – making it more complete; or it might be too detailed or application-specific and belong in another kind of model.
How can I ensure that an ontology is elegant?
This is related both to scope and to design. An ontology is elegant if it has the fewest possible concepts to cover the required scope with minimal redundancy and complexity. Whereas completeness is about making sure enough is in the ontology, elegance is about making sure that the ontology is not done until there is nothing else you can take out. Once an ontology gets big enough, it is hard to remember exactly what is already there, so duplication and redundancy can arise. It can also arise in more subtle ways – you can end up with three different ways of modeling essentially the same thing if it was approached independently from three different perspectives. This is especially true if there are different authors, but it can also happen with a single author if the three different perspectives are approached and modeled at different times.
How can I ensure that an ontology is easy to understand and use?
This is a complex and multi-faceted issue. The answer depends on the audience, who have varying degrees of a) knowledge in the domain, b) technical background, c) awareness of what the ontology is for and d) need to directly work with the ontology.
For everyone, and especially non-technical people, it is important for there to be natural language comments explaining the meaning of the concepts. It is helpful to have an overview of the ontology which has only the top few dozen classes and relationships (like a UML class diagram). It is good to have HTML documents that can be automatically generated from various tools. It should be possible to seamlessly move between levels of detail from the very general to the very specific ban back. Ideally, you want to have different layouts automatically created and tailored to different circumstances. There are many visualization tools available to help with some of these things, but much more remains to be done.
For the very technical individuals, who will be using the ontology on a day to day basis, it is important to be able to locate concepts that are similar to what they have in mind. For this, it helps to have the ontology classes and properties organized into a small number of disjoint hierarchies.
