Industry Knowledge Graph™ Case Study
Written by Michael Atkin
In 1978 the owner of the New England Patriots made a famous commercial after his wife gave him a Remmington electric razor – “I liked the razor so much, I bought the company.” In the case of the Industry Building Blocks (IBB), Semantic Arts liked the content so much, they turned it into a knowledge graph and became a full business partner with IBB.
The Industry Knowledge Graph™ (IndustryKG) is the perfect case study for people to understand (and visualize) the power of a knowledge graph for any organization. It is based on semantic standards – which are mature, sustainable and well governed. It consists of valuable content that has been transformed into a granular industry classification system around the intersection of companies, industries and products across the global economy. It has a graphical user interface that is easy for non-technical analysts to manipulate and do comparisons across a broad array of criteria. And it enables both value-based pricing and entitlement control to protect the intellectual property and ensure the continuity of recuring revenue.
Let’s take a look at the content first. IndustryKG contains 24,751 (and growing) industries consisting of 19 supersectors, 141 sectors, 619 subsectors and 3400 industry groupings. It was developed based on three decades of corporate planning expertise that defines industries at the granular level to help analysts understand the lines of business of the parent organization as well as the competitive industry landscape of each – including product substitutes and complements. The data has been augmented to include industry attractiveness rankings, buyer purchase criteria, product-related industry trends and industry growth forecasts.
The entire IndustryKG model of the global economy has been organized into a granular industry classification system based on Michael Porter’s five forces framework. Porter’s work has long been used as a tool for analyzing industry competitiveness and profitability by examining: (1) rivalry among existing competitors, (2) threat of new entrants, (3) threat of substitute products, (4) bargaining power of buyers, and (5) bargaining power of suppliers. Compare this to traditional classification systems (i.e. NAICS, GICS, SIC) that many deem as too course to appreciate true head-to-head competition. In our opinion, this rare and unique content is a natural candidate to be expressed as a knowledge graph.
The business challenge that IBB faced should be familiar to many people. The IBB content was embedded into spreadsheets and PDF files. It was data that was hard to manipulate for scenario-based analysis and for connecting the dots from industry – to company – to line of business – to competitors. Users couldn’t easily combine criteria to follow their business intuition. In addition, IBB wanted to protect the intellectual property and implement a flexible subscription-based business model. The product had to be easy to use by corporate planners, market researchers, M&A analysts, investment strategists and those involved in supply chain management, joint venture discovery and cost containment opportunities.
Users wanted to compare direct substitutions across industries, look at similar value chains and do side-by-side comparisons on a granular industry basis. All of these business objectives are solved with data-centric architecture that puts the data and the model at the core of the system and keeps the design as simple as possible to ensure that the content remains both reusable and extensible.
Semantic Arts was responsible for the data transformation strategy. We recognized that core to the IndustryKG is the industry classification system – which is designed to be a logical representation of factual truth (i.e. the products and services at the base of all industries). Ontologists working on the project were able to conceptualize the definition of an “industry” as defined by Porter’s five forces framework. This was accomplished by extracting the right information from the subject matter experts to understand the complexity of relationships and how to translate them as ontology. Translating the subject matter expert (SME) knowledge is one of the more important ‘create and align’ tasks of the ontologists.
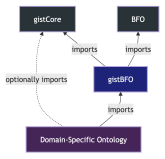
The logical structure of the original IBB – the existing spreadsheets of companies, industries and products is a natural ontology. The primary goal was to align the spreadsheet contents from CSV to triples and ensure that all the concepts were harmonized to their basic building blocks using gist (the open-sourced foundational ontology created by Semantic Arts) as an accelerator. All of the concepts needed for the expression of business and product relationships were aligned to the classes and properties of gist. For example, the concept of a “company” in the original IBB product aligns to the class of “organization” in gist. New properties such as ‘has market capitalization’ were created and market capitalization ‘has value’ of a ‘monetary amount’ in gist. This is the true expression of “meaning, not words” that characterizes conceptual modeling.
The pipeline management process was fairly straightforward. Our developers decrypted the password protection before converting the files to CSVs. The CSVs were processed to flatten the data and perform preliminary data validation (i.e. data types, values, expected ranges). This content was transformed into triples and uploaded into a triplestore repository to obtain new counts and calculate revenue and percentages at the group and industry level. The final data validation was performed using SHACL.
Semantic Arts assigned a number of developers onto the project to do design and layout. This was crucial because the user interface had to be ideal for business executives – in that data can be hard to use with lots of reconciliation or easy to use with the right tools. The design was also an iterative process between designers, developers and consumers for usability. We can’t emphasize enough the importance of engagement with end users to enable them to analyze, contrast and look at viewpoints from multiple perspectives. Our advice is to invest in the model from the beginning to ensure that business users can ask business questions and get business answers.
The business side of the equation was about implementing the subscription model and token purchase capability that IBB used as its pricing model. This included defining the shapes for the business model (i.e. users, accounts, organizations, addresses, identity, levels of permissioning, tokens purchased, number of facts consumed, authentication) to allow for payment according to depth, level and value of the content. This is a capability that is transferable to the full spectrum of entitlement requirements that exist for many industries.
Semantic Arts and IBB invite you to test drive the Industry Knowledge Graph for yourself. Click here to watch a video on how it works. Click here to get a free hands-on demo. Semantic Arts has championed the data-centric approach to managing enterprise data since its inception. We have been perfecting the methodology for data transformation but have never had any data of our own or a platform to showcase the possibility. The Industry Knowledge Graph™ is that platform. If you have a Knowledge Graph initiative and would like to populate it with industry and business intelligence information, we can provide knowledge graph triples. If you don’t yet have a Knowledge Graph project, we have an excellent starting point.