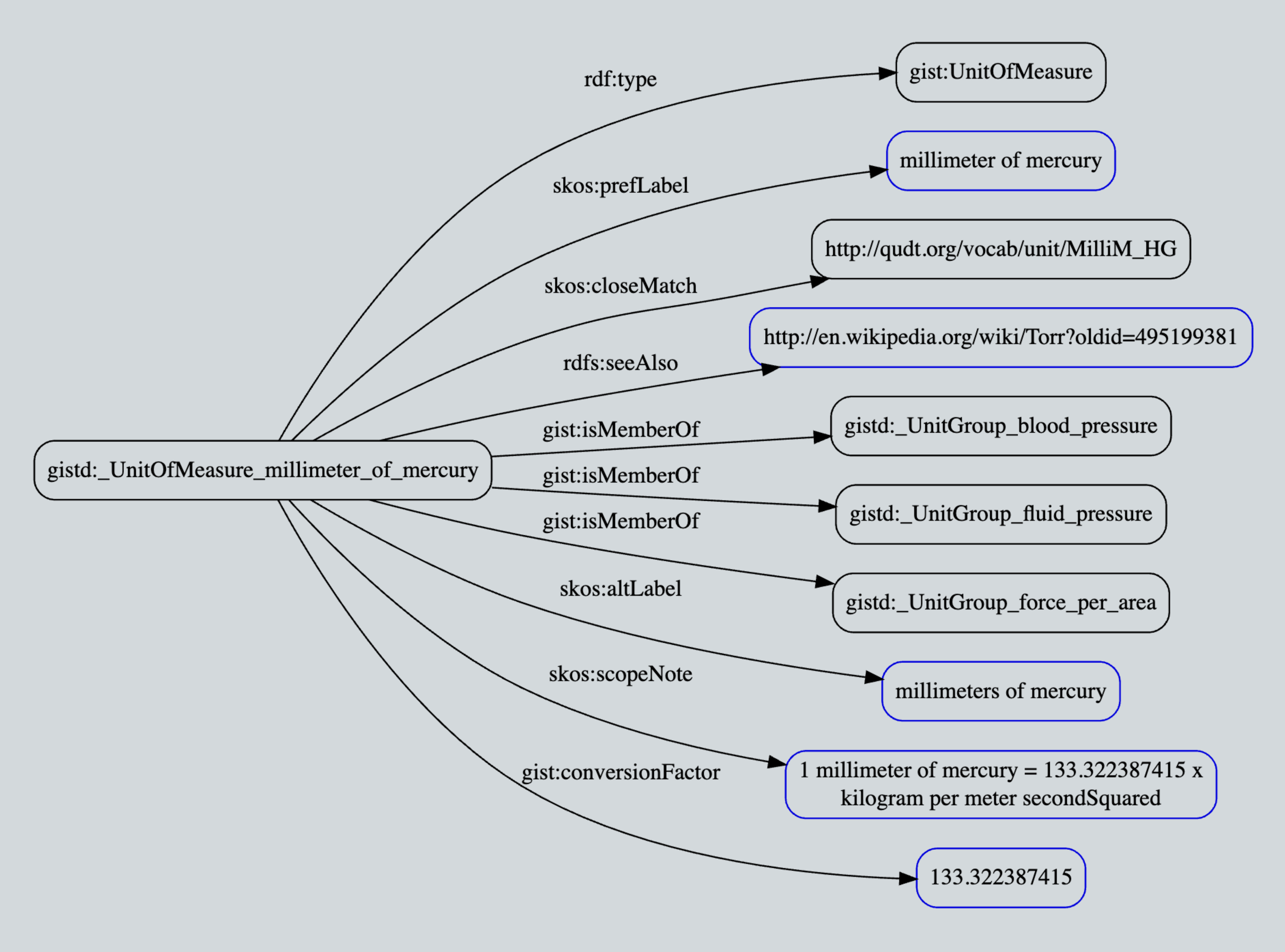
Knowledge Graph Modeling: Time Series Micro-Pattern Using gist
For any enterprise, being able to model time series is more than just important, in many cases it is critical. There are many examples, but some trivial ones include “Person is employed By Employer” (Employment date-range), “Business has Business Address” (Established Location date-range), “Manager supervises Member Of Staff” (Supervision date range), and so on. But many developers who dabble in RDF graph modeling end up scratching their heads — how can one pull that off if one can’t add attributes to an edge?
While it is true that one can always model things using either reification or leveraging RDF Quads (see my previous blog semantic rdf properties) now might be a good time to take a step back and explore how the semantic gurus at Semantic Arts have neatly solved how to
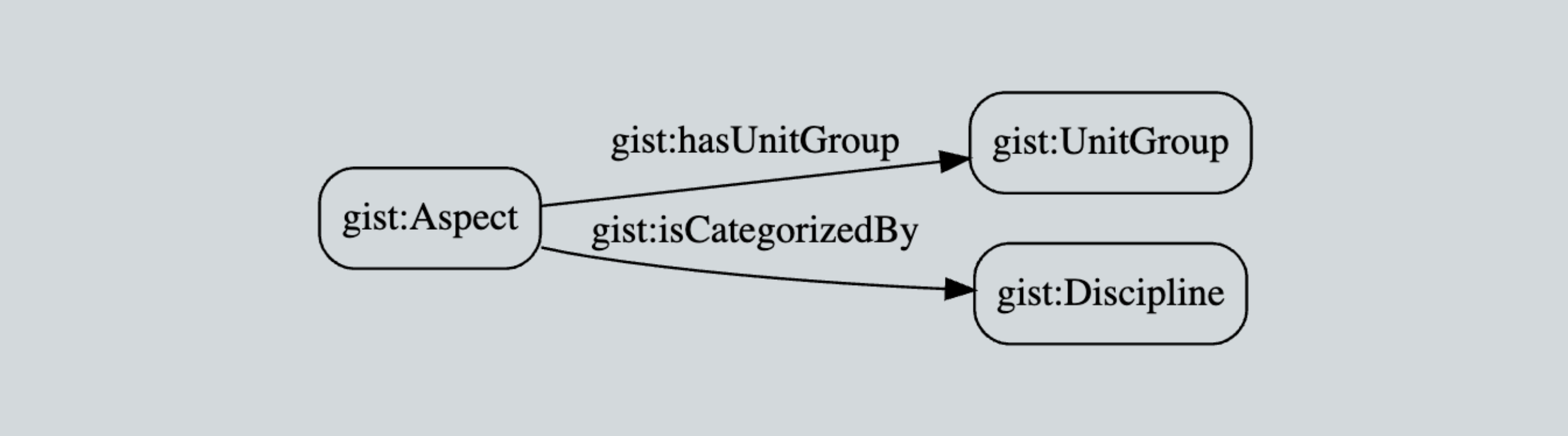
model time series starting with version 11 of GIST, their free upper-level ontology (link below).
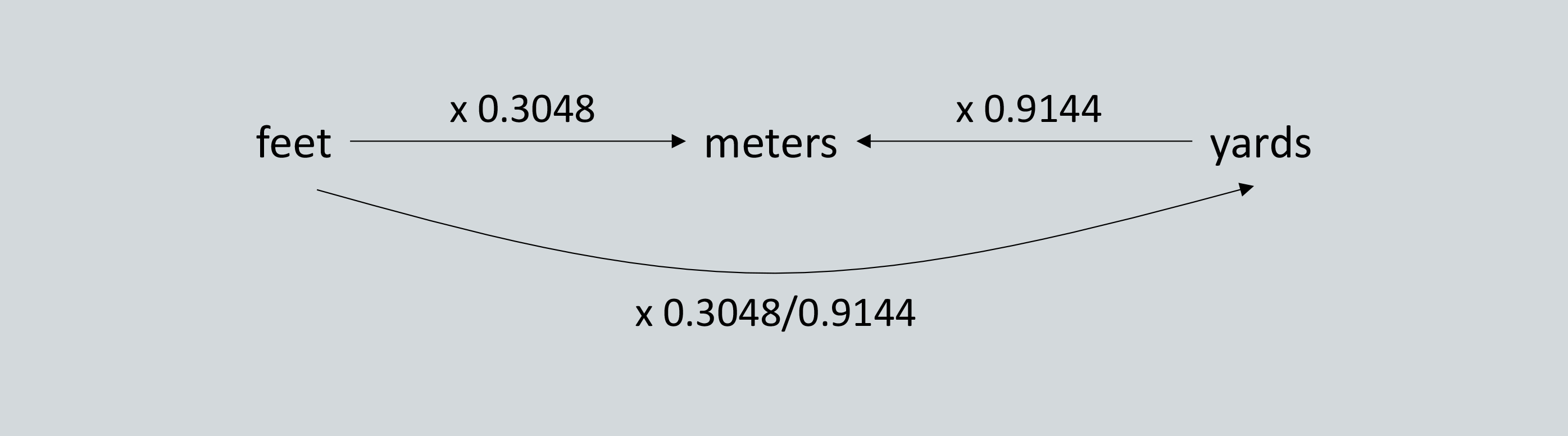
First a little history. The core concept of RDF is to “connect” entities via predicates (a.k.a. “triples”) as shown below. Note that either predicate could be inferred from the other, bearing in mind that you need to maintain at least one explicit predicate between the two, as there is no such thing in RDF as a subject without a predicate/object. Querying such data is also super simple.
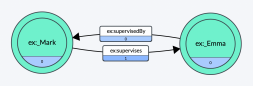
So far so good. In fact, this is about as simple as it gets. But what if we wanted to later enrich the above simple semantic relationship with time-series? After all, it is common to want to know WHEN Mark supervised Emma. With out-of-the-box RDF you can’t just hang attributes on the predicates (I’d argue that this simplistic way of thinking is why property graphs tend to be much more comforting to developers).
Further, we don’t want to throw out our existing model and go through the onerous task of re-modeling everything in the knowledge graph. Instead, what if we elevated the specific “supervises” relationship between Mark and Emma to become a first-class citizen? What would that look like? I would suggest that a “relation” entity that becomes a placeholder for the “Mark Supervises Emma” relationship would fit the bill. This entity would, in turn, reference Mark via a “supervision by” predicate while referencing Emma via a “supervision of” predicate.
Knowledge Graph Modeling: Time Series Micro-Pattern Using gist
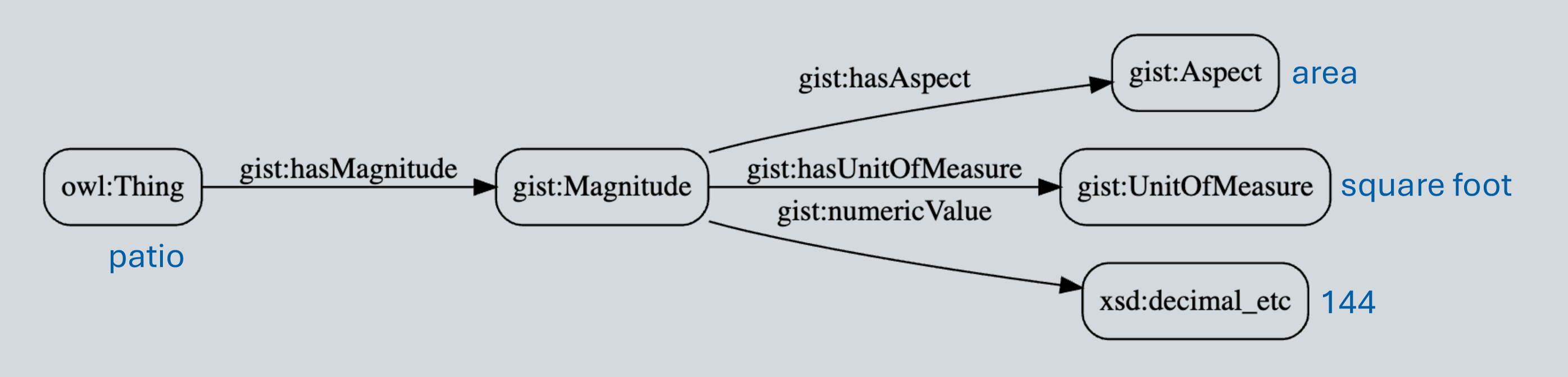
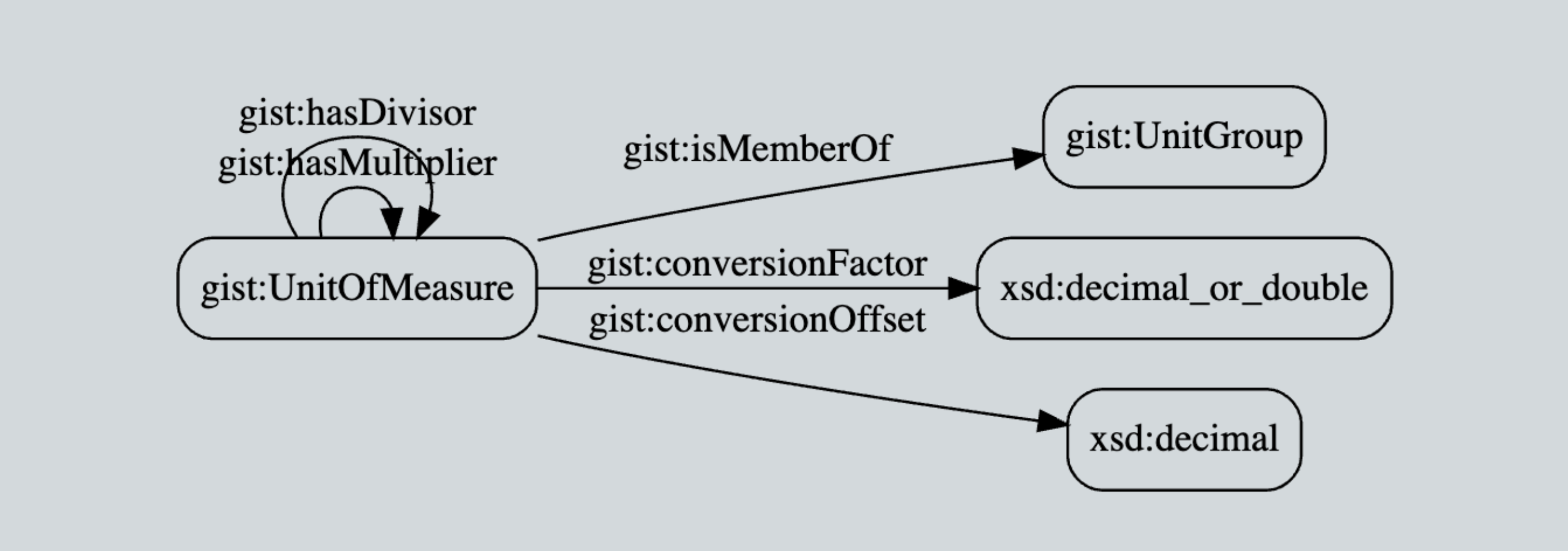
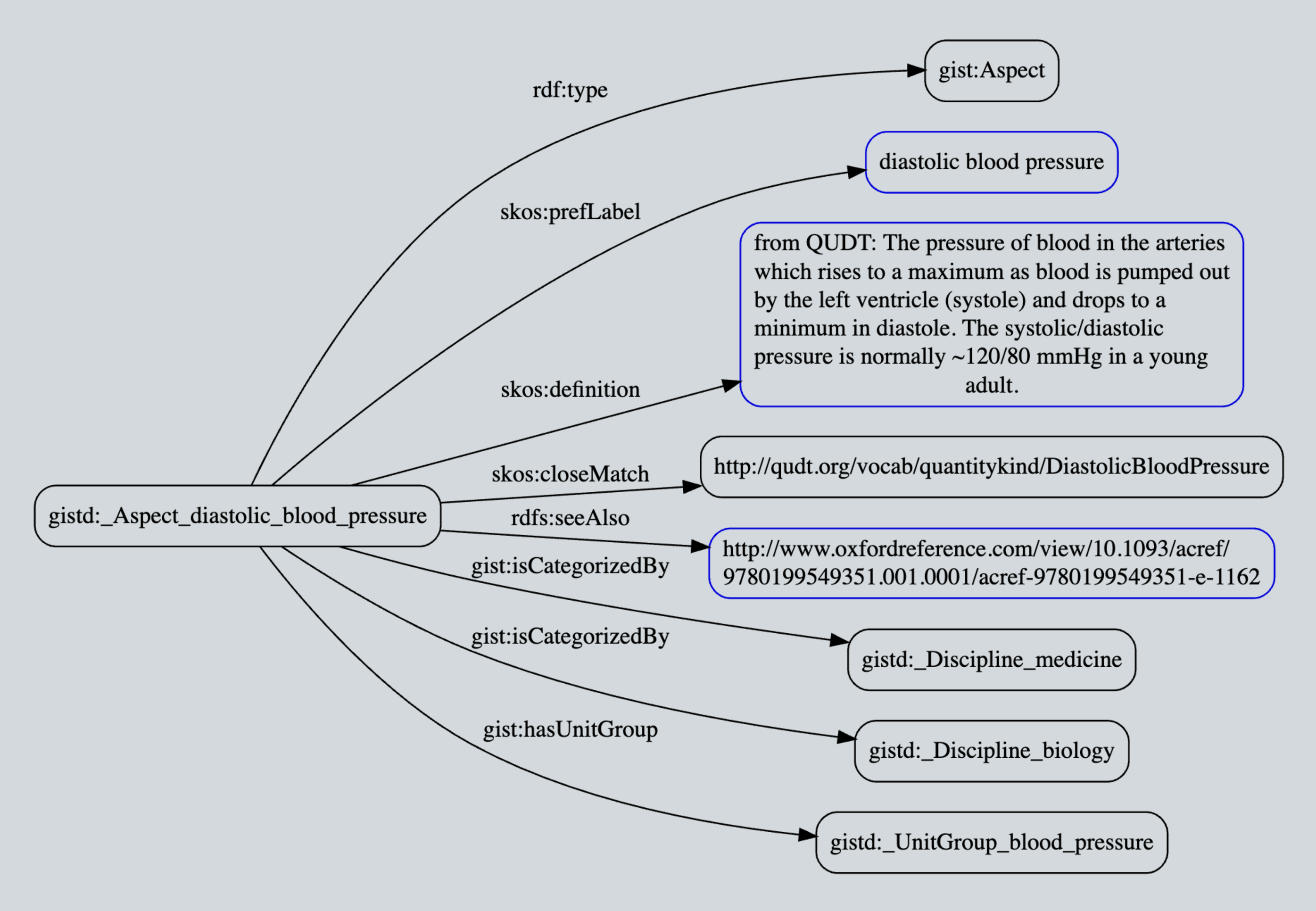
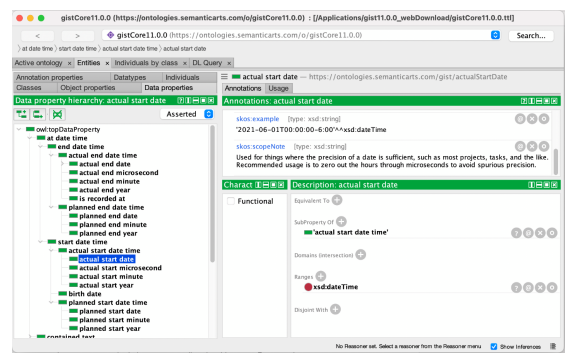
Ok, now that we have a first-class relation entity, we are ready to add additional time attributes (i.e. triples). Well, not so fast! The key insight that in GIST, is that the “actual end date” and “actual start date” predicates as used here specify the precision of the data property (rather than letting the data value specifying the precision), which in our particular use case, we want to be the overall date, not any specific time. Hence our use of gist:actualStartDate and gist:actualEndDate here instead of something more time-precise.
The rest is straightforward as depicted in the micro-pattern diagram shown immediately below. Note that in this case, BOTH the previous “supervised by” and “supervises” predicates connecting Mark to Emma directly can be — and probably should be — inferred! This will allow time-series to evolve and change over time while enabling queryable (inferred) predicates to always be up-to-date and in-sync. It also means that previous queries using the old model will continue to work. A win-win.
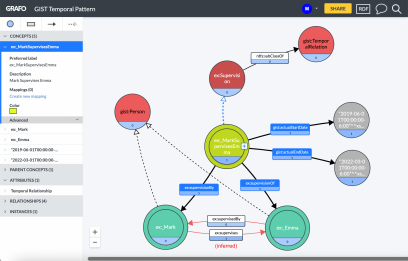
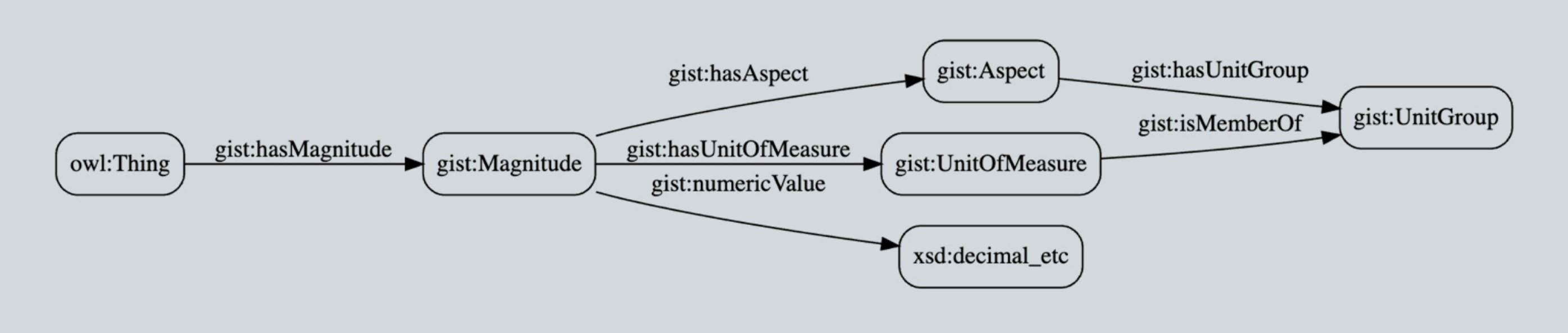
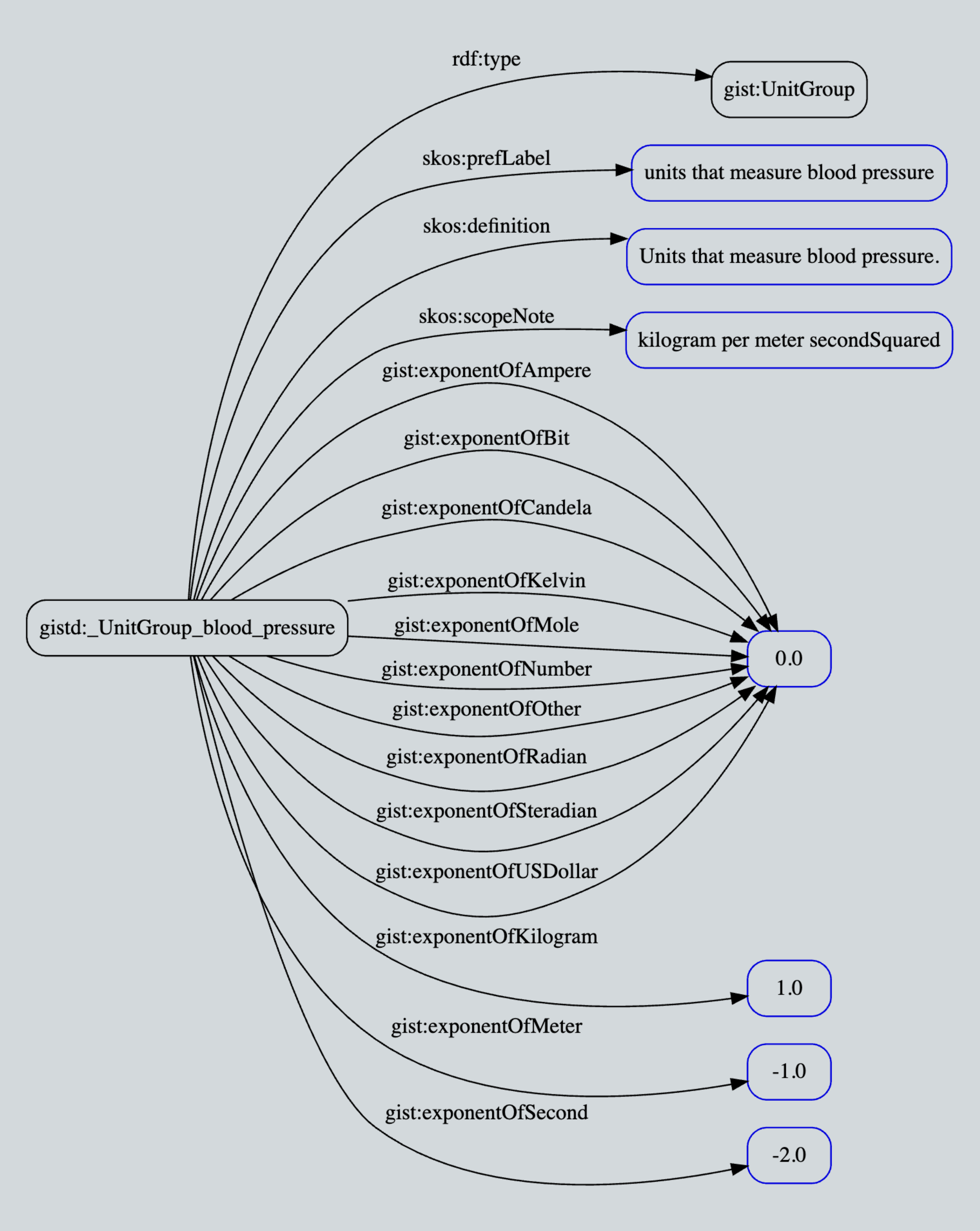
A clever ontological detail not shown here: A temporal relation such as “Mark supervises Emma” must be gist:isConnectedTo a minimum of two objects — this cardinality is defined in the GIST ontology itself and is thus inherited. The result is data integrity managed by the semantic database itself! Additionally, you can see the richness of the GIST “at date time” data properties most clearly in the expression of the hierarchical model in latest v11 ontology (see Protégé screenshot below). This allows the modeler to specify the precision of the start and end date times as well as distinguishing something that is “planned” vs. “actual”.
Overall, a very flexible and extensible upper ontology that will meet most enterprises’ requirements.
Knowledge Graph Modeling: Time Series Micro-Pattern Using gist
Further, this overall micro-pattern, wherein we elevate relationships to first-class status, is infinitely re-purposable in a whole host of other governance and provenance modeling use cases that enterprises typically require. I urge you to explore and expand upon this simple yet powerful pattern and leverage it for things other than time-series!
One more thing…
Given that with this micro-pattern we’ve essentially elevated relations to be first class citizens — just like in classic Object Role Modeling (ORM) — we might want to consider also updating the namespaces of the subject/predicate/object domains to better reflect the objects and roles. After all, this type of notation is much more familiar to developers. For example, the common notation object.instance is much more intuitive than owner.instance. As such, I propose that the traditional/generic use of “ex:” as used previously should be replaced with self-descriptive prefixes that can represent both the owner as well as the object type. This is good for readability and is self-documenting. And ultimately doing so may help developers become more comfortable with RDF/SPARQL over time. For example:
- ex:_MarkSupervisesEmma becomes rel:_MarkSupervisesEmma
- ex:supervisionBy becomes role:supervisionBy • ex:_Mark becomes pers:_Mark
- ex:_Mark becomes pers:_Mark
Where:
@prefix rel: <www.example.com/relation/>.
@prefix role: <www.example.com/role/>.
@prefix pers: <www.example.com/person/>.