
Once you have your ontology, you want to put it to use. We will describe a common scenario where data is extracted from various sources including relational databases. That data is then used in conjunction with an application instead of a traditional relational database. Things have advanced from just a few years ago when the main technologies were for representing the schema (RDF, RDFS), the data (RDF), and a query language (SPARQL). Two new and important standards have come out to address extracting data from relational databases and for specifying constraints that are not available in OWL.
One good way to go about building an ontology-based application is as follows:
- Create ontology
- Create SHACL constraints
- Create triples
- Build program logic and user interface
This parallels how to build a traditional application. The main difference is you are going to use a triple store to answer SPARQL queries instead of posing SQL queries to a relational database. Instead of creating conceptual, logical, and physical data models along with various integrity constraints, you will be building an ontology and SHACL constraints. Instead of having just one database and one data model per application, you can reuse either or both for multiple applications around the enterprise.
Create Ontology
Create the ontology for the chosen subject matter. Start with a core ontology that can be extended and used in a variety of applications across the enterprise. This is similar to an agile approach, in that you start small and extend. From the start, think about the medium and long term so that additions are natural extensions of the core ontology, which should be relatively stable.
Create SHACL Constraints
The ontology is modeling the real world, independently from any particular application. To build a specific application, you will be choosing a subset of the ontology classes and properties to use. Many but not all of the properties that are optional in the real world will remain optional in your application. Some properties that necessarily hold in the real world as reflected in the ontology will be of no interest for a particular application.
SHACL is a rich and complex standard with many intended uses. Three key ones are:
- Communicate what part of the ontology is to be used in the application.
- Communicate exactly what the triples need to look like that will be created and loaded into the triple store.
- Communicate to a SHACL engine exactly what integrity constraints are to be respected.
This process also forces you to examine all the aspects of the ontology that are needed for the application. It usually uncovers mistakes or gaps in the ontology. See Figure 1.
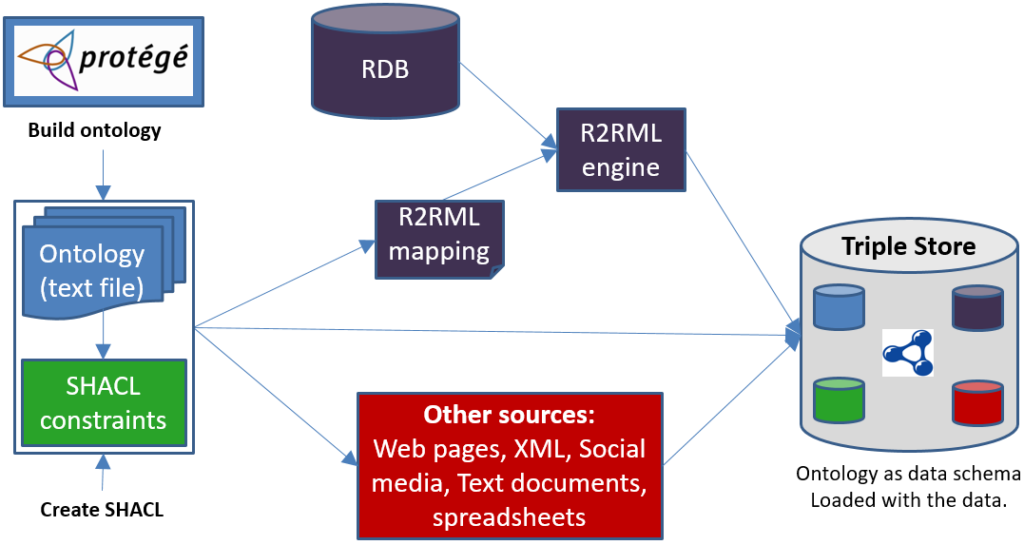
Figure 1: Creating Ontology, Constraints, and Triples
Create Triples
Triples can come from many sources, including text documents, web pages, XML documents, spreadsheets, and relational databases. The latter two are the most common, and the vendors have supplied tools to support this process. The W3C has also created a standard for mapping a relational schema to an ontology so that triples may be extracted directly from a relational database. That standard is called R2RML[1]. See Figure 2 to see how this works. An R2RML specification for this simple example would indicate the following:
- Each row in the corporation table will be an instance of the :Corporation.
- The IRI for each instance of :Corporation will use the myd: namespace, and the local name (after the colon) is to be an underscore followed by the value in the ‘CorporationID’ column.
- The ‘Subsidiary Of’ column corresponds to the :isSubsidiaryOf property.
- The ‘CEO’ column corresponds to the :hasCEO property.
- There is a foreign key connecting values of the ‘CEO’ column to a Person table.
With this information, the R2RML engine can reach into the relational database table and extract triples as indicated in Figure 2. Importantly, exactly one triple results from each cell in the table. If there's a NULL, no triple is created.
If you need to create triples from spreadsheets, you can use vendor tools, create your own tool, or write ad hoc scripts. There is not as much by way of out-of-the-box standards and tools for extracting triples from web pages, XML documents, and text documents. Specialized scraping and natural processing tools may be available.
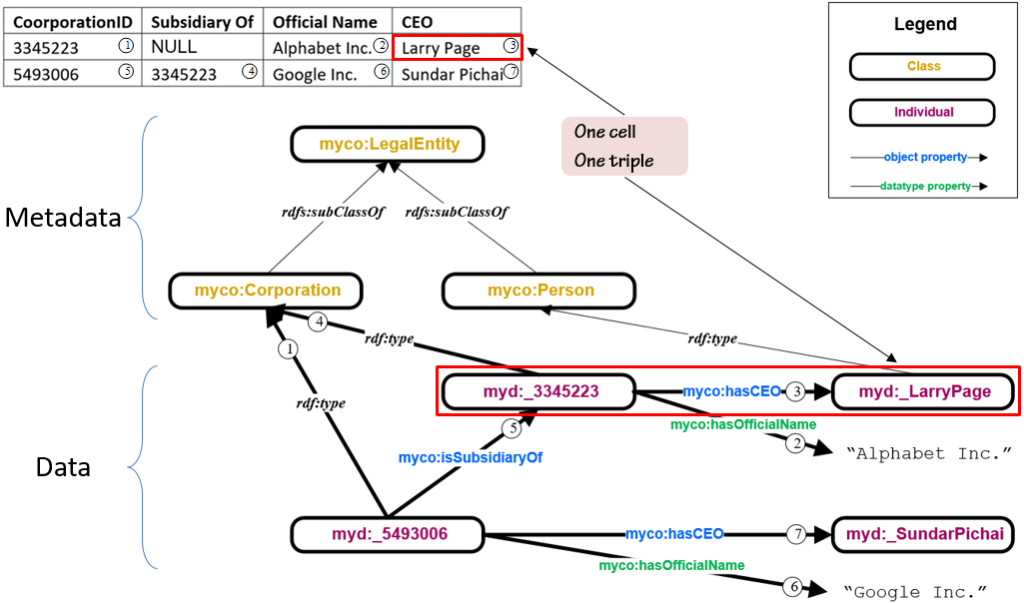
Figure 2: Tables to Triples
Build Program Logic & User Interface
This phase works much like the development of any other application. The main difference is that instead of querying a relational store using SQL, you are using SPARQL to query a triple store. See Figure 3.

Figure 3: Semantic Application Architecture