

To load existing data into a knowledge graph without writing code, try using the tarql program. Tarql takes comma-separated values (csv) as input, so if you have a way to put your existing data in csv format, you can then use tarql to convert the data to semantic triples ready to load into a knowledge graph. Often, the data starts off as a tab in an Excel spreadsheet, which can be saved as a file of comma-separated values.
This blog post is for anyone familiar with SPARQL who wants to get started using tarql by learning a simple three-step process and seeing enough examples to feel confident about applying it.
Why SPARQL? Because tarql gets its instructions for how to convert csv data to triples via SPARQL statements you write. Tarql reads one row of data at a time and converts it to triples; by default the first row of the comma-separated values is interpreted to be variables, and subsequent rows are interpreted to be data.

Here are three steps to writing the SPARQL:
1. Understand your csv data and write down what one row should be converted to.
2. Use a SPARQL CONSTRUCT clause to define the triples you want as output.
3. Use a SPARQL WHERE clause to convert csv values to output values.
That’s how to SPARQL with tarql.
Example:
1. Review the data from your source; identify what each row represents and how the values in a row are related to the subject of the row.

In the example, each row includes information about one employee, identified by the employee ID in the first column. Find the properties in your ontology that will let you relate values in the other columns to the subject.
Then pick one row and write down what you want the tarql output to look like for the row. For example:
exd:_Employee_802776 rdf:type ex:Employee
ex:name “George L. Taylor” ;
ex:hasSupervisor exd:_Employee_960274 ;
ex:hasOffice “4B17” ;
ex:hasWorkPhone “906-555-5344” ;
ex:hasWorkEmail “[email protected]” .
The “ex:” in the example is an abbreviation for the namespace of the ontology, also known as a prefix for the ontology. The “exd:” is a prefix for data that is represented by the ontology.
2. Now we can start writing the SPARQL that will produce the output we want. Start by listing the prefixes needed and then write a CONSTRUCT statement that will create the triples. For example:
prefix ex: <https://ontologies.company.com/examples/>
prefix exd: <https://data.company.com/examples/>
prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
prefix xsd: <http://www.w3.org/2001/XMLSchema#>
construct {
?employee_uri rdf:type ex:Employee ;
ex:name ?name_string ;
ex:hasSupervisor ?supervisor_uri ;
ex:hasOffice ?office_string ;
ex:hasWorkPhone ?phone_string ;
ex:hasWorkEmail ?email_string .
}
Note that the variables in the CONSTRUCT statement do not have to match variable names in the spreadsheet. We included the type (uri or string) in the variable names to help make sure the next step is complete and accurate.
3. Finish the SPARQL by adding a WHERE clause that defines how each variable in the CONSTRUCT statement is assigned its value when a row of the csv is read. Values get assigned to these variables with SPARQL BIND statements.
If you read tarql documentation, you will notice that tarql has some conventions for converting the column headers to variable names. We will override those to simplify the SPARQL by inserting our own variable names into a new row 1, and then skipping the original values in row 2 as the data is processed.

Here’s the complete SPARQL script:
prefix ex: <https://ontologies.company.com/examples/>
prefix exd: <https://data.company.com/examples/>
prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
prefix xsd: <http://www.w3.org/2001/XMLSchema#>
construct {
?employee_uri rdf:type ex:Employee ;
ex:name ?name_string ;
ex:hasSupervisor ?supervisor_uri ;
ex:hasOffice ?office_string ;
ex:hasWorkPhone ?phone_string ;
ex:hasWorkEmail ?email_string .
}
where {
bind (xsd:string(?name) as ?name_string) .
bind (xsd:string(?office) as ?office_string) .
bind (xsd:string(?phone) as ?phone_string) .
bind (xsd:string(?email) as ?email_string) .
bind(str(tarql:expandPrefix(“ex”)) as ?exNamespace) .
bind(str(tarql:expandPrefix(“exd”)) as ?exdNamespace) .
bind(concat(“_Employee_”, str(?employee)) as ?employee_string) .
bind(concat(“_Employee_”, str(?supervisor)) as ?supervisor_string) .
bind(uri(concat(?exdNamespace, ?employee_string)) as ?employee_uri) .
bind(uri(concat(?exdnamespace, ?supervisor_string))as ?supervisor_uri) .
# skip the row you are not using (original variable names)
filter (?ROWNUM != 1) # ROWNUM must be in capital letters
}
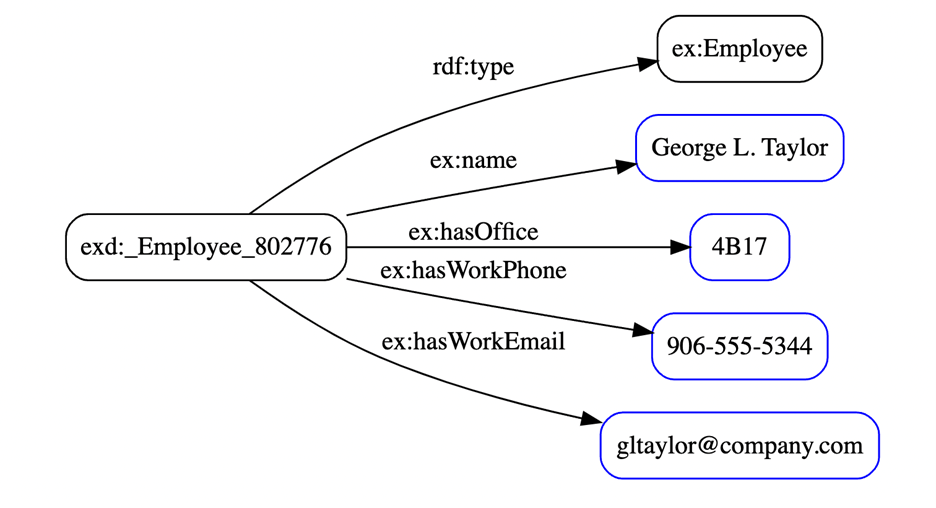
And here are the triples created by tarql:
exd:_Employee_802776 rdf:type ex:Employee ;
ex:name “George L. Taylor” ;
ex:hasOffice “4B17” ;
ex:hasWorkPhone “906-555-5344” ;
ex:hasWorkEmail “[email protected]” .
exd:_Employee_914053 rdf:type ex:Employee ;
ex:name “Amy Green” ;
ex:hasOffice “3B42” ;
ex:hasWorkPhone “906-555-8253” ;
ex:hasWorkEmail “[email protected]” .
exd:_Employee_426679 rdf:type ex:Employee ;
ex:name “Constance Hogan” ;
ex:hasOffice “9C12” ;
ex:hasWorkPhone “906-555-8423” .
If you want a diagram of the output, try this tool for viewing triples.
Now that we have one example worked out, let’s review some common situations and SPARQL statements to deal with them.
To remove special characters from csv values:
replace(?variable, ‘[^a-zA-Z0-9]’, ‘_’)
To cast a date as a dateTime value:
bind(xsd:dateTime(concat(?date, ‘T00:00:00’)) as ?dateTime)
To convert yes/no values to meaningful categories (or similar conversions):
bind(if … )
To split multi-value fields:
apf:strSplit(?variable ‘,’)
Another really important point is that data extracts in csv format typically do not contain URIs (the unique permanent IDs that allow triples to “snap together” in the graph). When working with multiple csv files, make sure to keep track of how you are creating the URI for each type of instance and always use exactly the same method across all of the sources.
Practical tip: name files to make them easy to find, for example:
employee.csv
employee.tq SPARQL script containing instructions for tarql
employee.sh shell script with the line “tarql employee.tq employee.csv”
Excel tip: to save an Excel sheet as csv use Save As / Comma Separated Values (csv).
So there it is, a simple three-step method for writing the SPARQL needed to convert comma-separated values to semantic triples. The beauty of it is that you don’t need to write code, and since you need to use SPARQL for querying triple stores anyway, there’s only a small additional learning curve to use it for tarql.
Special thanks to Michael Uschold and Dalia Dahleh for their excellent input.
For more examples and more options, see the nice writeup by Bob DuCharme or refer to the tarql site.